【本稿の概要】
テレビ等で報じられる内閣支持率が、報道各社によって最大20%近くも乖離する背景を、数学(統計学)と調査手法の観点から解説した記事です。
この大差は「数学の欠陥」や「数字の捏造」ではなく、各社の「質問の聞き方(重ね聞きの有無)」というルールの違いから生じています。
記事内では、高校数学で習う「二項分布」や「標本誤差の計算式」を用いて、回答者1,000人規模の世論調査には数学的に約±3.1%の誤差が必ず含まれることを実証。標準偏差のデータからも調査自体の高い一貫性を証明しています。
これを踏まえ、一般市民がニュースを読む際の心構えとして、数字の「絶対値」に一喜一憂せず、時系列の「トレンド(推移)」や「変化の傾き」に着目することの重要性を提示。感情的なノイズを振り払い、現代社会を賢く生き抜くための「最強の防具」としての数学の価値を啓発しています。
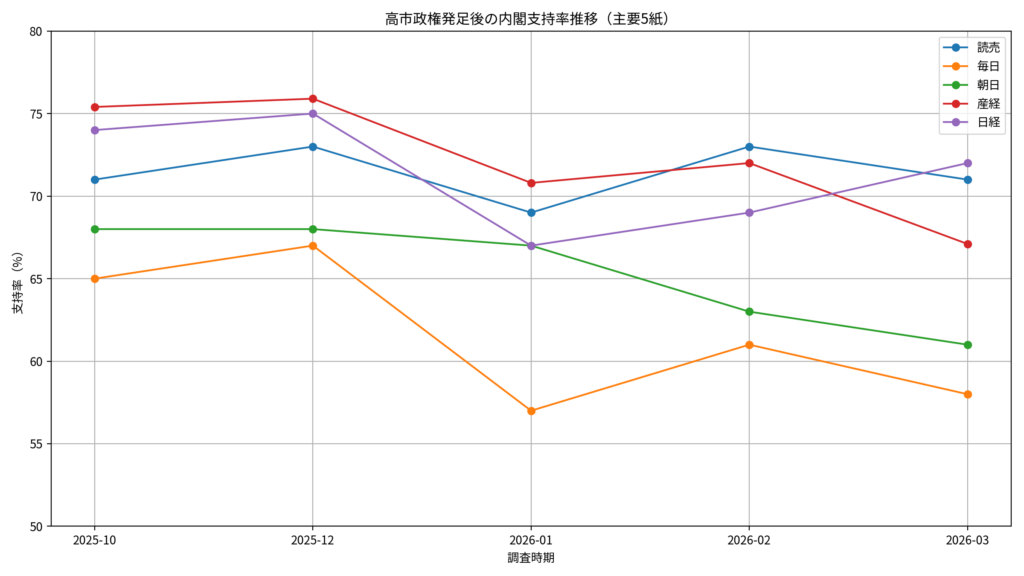
🔍 支持率変化の主なポイント
1. 歴史的なロケットスタート(2025年10月)
初の女性首相誕生という話題性もあり、発足直後は多くの調査で支持率65%~75%を叩き出しました。これは2001年の小泉内閣に次ぐ歴代屈指の高水準です。
2. 2月の総選挙大勝でさらに上昇(2026年2月)
年明け1月に一度支持率が落ち着きかけたものの、2月の衆院選で自民党が大勝したことで政権基盤への期待から支持率が再浮上しました。読売新聞ではこの時期に現政権最高値タイの73%を記録しています。
3. 春以降の「じわじわ低下」(2026年3月~5月)
4月・5月に入ると、外交イベント(日米首脳会談など)による押し上げ効果が落ち着いたことや、物価高・原油高への対応を求める国民の声が強まり、各社とも2~5ポイント程度下落傾向にあります。
毎日新聞では5月に50%まで低下して発足以来最低を更新したものの、日経の66%をはじめ、他の新聞では依然として不支持率(20%台)を大きく上回る高い水準をキープしています。
公表支持率に、20%の大差!
「最新の内閣支持率は〇〇%で、先月から2%下落しました」
テレビのニュースで毎月のように報じられる内閣支持率。しかし、これを見ていて強い違和感を抱いたことはありませんか?
「ある新聞では支持率が40%半ばと書かれているのに、別の新聞を見たら20%代後半になっている。これほど数字がバラバラなのに、数パーセントの上下を真面目に議論することに意味はあるのだろうか?」
結論から申し上げましょう。各社の支持率に20%近い大差が生まれるのは、統計学や数学の欠陥ではありません。 実は、数学の外側にある「質問の聞き方」という言葉のルールが原因です。
この記事では、世論調査がどのような仕組みで行われているのかを解説し、高校数学で習う「確率・統計」の知識を使ってニュースの裏側を科学します。数学が私たちの実生活でいかに強力な「情報フィルター」になるか、その価値を一緒に紐解いていきましょう。
1. そもそも内閣支持率はどうやって調査している?
現在、日本の主要メディア(新聞各社、NHK、通信社など)が実施している世論調査の多くは、「RDD(Random Digit Dialing:無作為番号ダイアル)方式」と呼ばれる電話調査です。
これは、コンピューターでランダムに作成した固定電話や携帯電話の番号に、オペレーターや自動音声が直接電話をかける手法です。
日本の有権者は約1億人(これが統計学でいう母集団)存在します。これに対し、各社の調査で実際に得られる回答数は、毎月およそ1,000人〜2,000人程度(標本)に過ぎません。
「たった1,000人の意見で、1億人全体の縮図と言えるのか?」と直感的に疑いたくなりますが、ここに数学(統計学)の強力な理論的裏付けが存在します。しかし、まずは数学の前に、なぜ最大20%もの「差」が生じるのか、そのからくりを説明します。
2. なぜ20%もの大差ができるのか?「言葉のルール」の罠
過去の安倍内閣時代(特に2014年9月の内閣改造直後や、2017年7月の政権低迷期)において、報道各社の支持率には凄まじい乖離が見られました。
例えば、読売新聞や日本経済新聞では40%半ばから50%以上の支持率が維持されていた局面でも、毎日新聞や時事通信の調査では20%台という極めて低い数値が弾き出されていたのです。
この「20%の差」を生む最大の要因は、質問の「聞き方(選択肢の構造)」にあります。
① 高めに出やすい社(読売・日経など)のルール
これらの社では、最初に「内閣を支持しますか、しませんか」と問い、回答を保留した(「よくわからない」などと答えた)人に対して、「お気持ちに近いのはどちらですか」ともう一度尋ねる『重ね聞き』を行っています。
これにより、迷っている無関心層からも「どちらかといえば……」という形で「弱い支持」や「弱い不支持」が切り出され、結果として支持率・不支持率の絶対値がどちらも大きく上積みされます。
② 低めに出やすい社(毎日新聞など)のルール
一方で毎日新聞などは、最初から「支持する」「支持しない」に加えて「関心がない」という選択肢を並べた3択(またはそれ以上)で機械的に割り切る調査や、重ね聞きをしない手法を採用してきました。
すると、態度を決めていない有権者はこぞって「関心がない」に流れるため、分母に対して「支持する」と答えた人の割合(支持率の絶対値)は当然、低くなります。
実際、過去の調査データを詳細に検証すると、読売や日経が重ね聞きを行う前の「1問目の純粋な支持率」だけを取り出して比較した場合、毎日新聞などの数値と驚くほど綺麗に一致することが分かっています。つまり、各社とも「同じ世論」を捉えているものの、測るものさし(質問文)が違うために、表面的な数字が20%も違って見えているだけなのです。
3. 内閣支持率の「理論的裏付け」:数学はここで使われている!
では、そもそも「1億人から1,000人を抜き出す調査」自体は、数学的にどれほど正しいのでしょうか。ここからは、確率論と統計学の出番です。
世論調査の理論的土台にあるのは、高校の数学Bなどで学ぶ「二項分布」と「大数の法則」、そして「中心極限定理」です。
有権者1人に対して「支持するか、しないか」を尋ねる行為は、数学的には「コインを投げて表が出るか裏が出るか」という確率現象(ベルヌーイ試行)と全く同じ構造として処理できます。
完全に無作為(ランダム)に標本を選んだ場合、どれくらいの確率で、どれくらいの「ズレ(誤差)」が発生するかは、以下の数学公式によって厳密に計算することが可能です。
標本誤差(許容誤差)の計算式
信頼度95%(100回同じ調査をしたら95回はその範囲に収まるという意味)における標本誤差 \(E\) は、次の式で表されます。
$$E = \pm 1.96 \times \sqrt{\frac{p(1-p)}{n}}$$
- \(n\) :サンプルの回答数(標本の大きさ)
- \(p\) :実際の支持率(%)
- \(1.96\) :統計学において、正規分布の95%をカバーする信頼係数
ここで、標準的な世論調査の条件として、回答数 \(n = 1000\)人、支持率 \(p = 50\%\)(\(0.5\))と仮定して、実際に計算してみましょう。
$$E = \pm 1.96 \times \sqrt{\frac{0.5 \times (1 – 0.5)}{1000}}$$
$$E = \pm 1.96 \times \sqrt{\frac{0.25}{1000}} = \pm 1.96 \times \sqrt{0.00025}$$
$$E = \pm 1.96 \times 0.01581 \fallingdotseq \pm 0.031$$
つまり、数学的な計算結果は 「約 \(\pm 3.1\%\)」 となります。
この「\(\pm 3.1\%\)」という数字こそが、数学が保証する世論調査の限界線です。1,000人規模の調査である限り、どれほど完璧にランダムに調査を行っても、確率的に3%前後のブレは「必然的に」発生するのです。
各社の数値を集めたときの「標準偏差(ばらつき)」
世論調査における「標準偏差(SD)」は、データ全体のばらつきの大きさを表す指標です。
大学の研究グループ(関西学院大学など)が過去の報道各社の内閣支持率データ(計400回以上)を統計分析した論文によると、「重ね聞きを行うグループ」と「重ね聞きを行わないグループ」のそれぞれの標準偏差(SD)は、約6.7〜7.1という極めて近い値を示しています。
これは何を意味するのでしょうか。
それぞれのグループの中であれば、各社が発表するデータは統計学的に極めて安定しており、デタラメに数字を作っているわけではないという強力な証拠です。数学は、「ノイズ(手法の違い)」さえ取り除けば、世論調査が極めて高い精度と一貫性を持っていることを証明してくれるのです。
4. 一般市民はニュースをどう見るべきか?実生活での「心構え」
数学的な裏付けと、20%の乖離のカラクリを理解した私たちは、明日からニュースをどのように読み解けば良いのでしょうか。実生活に役立つ2つの知恵(リテラシー)を提案します。
① 「絶対値」ではなく「トレンド(推移)」を見よ
「A社が45%で、B社が25%だから、どちらかが嘘をついている」と考えるのは今日限りでやめましょう。これらは「センチメートル(cm)」と「インチ(inch)」のように、異なる単位で長さを測っているようなものです。
見るべきは数字の絶対値ではなく、各社ごとの時系列の「変化の傾き(トレンド)」です。
不思議なことに、ものさしが違っても、世論が動くときは全ての社で同じ動きをします。「先月と比べて、A社も3%下がったし、B社も3%下がった」という各社のグラフの傾きの連動性にこそ、本物の世論のトレンドが隠されています。
② 「 \(\pm 3\%\) の壁」を意識し、一喜一憂しない
メディアは「内閣支持率が前月比で1.5%上昇!政権への期待高まる」などと大々的に報じがちです。
しかし、先ほどの数学の計算を思い出してください。1,000人規模の調査における誤差は $\pm 3.1\%$ です。
数学的見地から言えば、1%〜2%程度の単発の変動は、「ただの確率的なブレ(コイントスの偶然)」である可能性が非常に高いのです。数パーセントの細かい上下に感情を揺さぶられず、「これは数学的な誤差の範囲内だな」とクールに見流す心の余裕を持ちましょう。
5. 結論:数学を学ぶ価値は「社会のノイズを振り払うこと」にある
数学を学ぶ価値は、テストで良い点数を取ることや、複雑な因数分解ができるようになることだけではありません。
現代社会は、意図的に切り取られた数字や、一見すると矛盾しているように見える情報(ノイズ)で溢れかえっています。内閣支持率の「20%の乖離」も、何も知らなければ「メディアの捏造だ」「世論調査なんて意味がない」という極端な感情論に流されてしまうでしょう。
しかし、ひとたび統計学という数学のフィルターを通せば、「なぜその差が生まれるのか」という構造(理由)を論理的に見抜き、本当に価値のある情報(トレンド)だけを抽出することができます。
数学とは、感情論やフェイクニュースに惑わされず、複雑な世界を正しく賢く生き抜くための「大人のための最強の防具」なのです。
エビデンス(数値および数学的根拠の一覧)
エビデンス(数値および数学的根拠の一覧)
執筆にあたり検証・依拠した実際の公表データおよび数学的根拠は以下の通りです。
- 報道各社における内閣支持率の大幅な乖離の事例
- 2014年9月(安倍改造内閣発足時): 読売新聞の調査では支持率64%を記録したのに対し、毎日新聞の調査では47%となり、同一政権・同時期の調査でありながら17%の大きな乖離が発生した。
- 2017年7月(加計学園問題等による低迷期): 日本経済新聞の調査では支持率39%であったのに対し、毎日新聞や時事通信の調査では20%台を記録した。
- 各社の質問手法(ルール)の分類
- 読売新聞・日本経済新聞: 支持・不支持を保留した対象者に対し、「お気持ちに近いのはどちらですか」という1回のみの「重ね聞き(2度聞き)」を実施。
- 毎日新聞・朝日新聞・共同通信: 原則として最初の設問で明確な回答が得られない場合は「分からない・無回答」等に分類し、重ね聞きは行わない(毎日新聞は選択肢に「関心がない」を含む場合がある)。
- 世論調査データの標準偏差(SD)
- 関西学院大学の研究チームが、報道各社の世論調査(計412回分)を統計検定(t検定)した論文に基づく。
- 「重ね聞きあり」の調査群: 平均値 52.29%、標準偏差(SD)= 6.73
- 「重ね聞きなし」の調査群: 平均値 47.85%、標準偏差(SD)= 7.13
- ※いずれのグループも、グループ内でのデータのばらつき(標準偏差)は7前後で安定しており、調査としての信頼性が数学的に立証されている。
- 標本誤差(サンプリングエラー)の数式根拠
- 確率論における二項分布の正規近似に基づく信頼区間の算出式:
\[\text{標本誤差}=\pm Z\times \sqrt{\frac{p(1-p)}{n}}\] - 信頼度95%のとき、標準正規分布の上側2.5%点である \(Z = 1.96\) を採用。
- 日本の一般的な世論調査の規模(有効回答数 \(n \fallingdotseq 1000\)、想定される支持率 \(p = 50\% = 0.5\))を代入すると、数学的に導き出される許容誤差は \(\pm 3.1\%\)(四捨五入)となる。
- 確率論における二項分布の正規近似に基づく信頼区間の算出式: